从一次 tenantId 联调 bug,看我们该怎么给 AI 项目补齐 harness
前几天我读了 OpenAI 那篇文章:Harness engineering: leveraging Codex in an agent-first world。
我读完最大的感受不是“AI 又强了”,而是另一个更接地气的结论:
很多时候,不是模型不够强,而是你的工程环境没有把“正确性”暴露给模型。
这两天我正好在自己项目里处理一个非常典型的问题:运营端新增门店和校验门店名时,如果和其它租户重名会误报;员工后台接口也有类似的租户范围问题。表面上看只是个 tenantId bug,但整个过程把一个事实暴露得很彻底:
AI 想高效干活,前提不是 prompt 更长,而是 harness 更清楚。
一、这次 bug 表面是租户问题,实质是“环境表达不清”
最初的现象其实很迷惑:
- 运营端调用
admin/store/checkName - 明明传了
tenantId - 但接口判重却像是按别的租户在查
如果只看 Controller 参数,你会以为“不是都传进来了吗”。
但真正往下追,就会发现系统里其实混着两套租户来源:
- 请求里显式传入的
tenantId - 线程上下文里的
TenantContextHolder
理论上,TenantContextHolder 也不是错的。因为网关或 filter 确实会从 header 里解析租户并写入上下文。问题在于:
后台管理接口的业务语义,不是‘当前会话属于哪个租户’,而是‘当前运营账号要操作哪个目标租户的数据’。
这两个概念,在多租户后台系统里根本不是一回事。
所以这次真正的问题不是一句“代码写错了”,而是:
系统没有把“哪一个租户才是业务真相”表达得足够显式。
这就是 harness 问题。
二、OpenAI 那篇文章对我最有启发的,不是模型能力,而是“把环境当产品做”
那篇文章里有几层意思我特别认同,我这里不逐字复述,只说我自己的理解。
1)Agent 的上限,很大程度取决于它能不能直接看到真实运行环境
如果模型只能读代码,看不到:
- 实际 HTTP 请求长什么样
- token 从哪里来
- 当前服务到底连的是哪套数据库
- 逻辑删除字段的业务语义是什么
那它就很容易陷入一种“静态推理正确,动态结论错误”的状态。
这次我们项目里就连续遇到了:
- 代码已经改了,但运行中的服务没重启
checkName返回true/false的语义,调用方理解反了- 数据库里能查到门店记录,但那条记录其实已经逻辑删除
这些都不是大算法问题,而是工程上下文没有被收束成一个可验证的工作台。
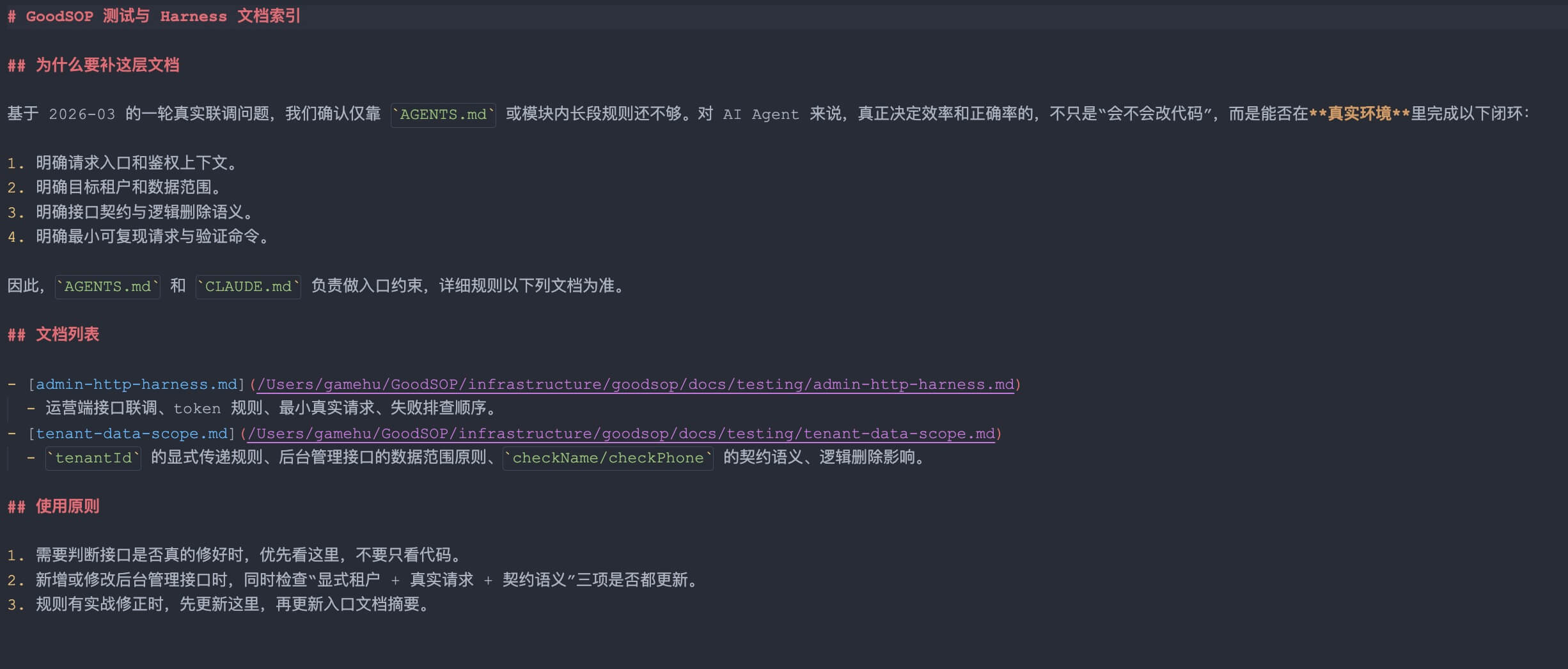
2)入口文档不该是经验大杂烩,而应该是导航页
以前很多项目的 AGENTS.md、模块说明文档,最后都会越写越长。
每次踩坑补一条,最后谁都不想看,AI 也很难稳定执行。
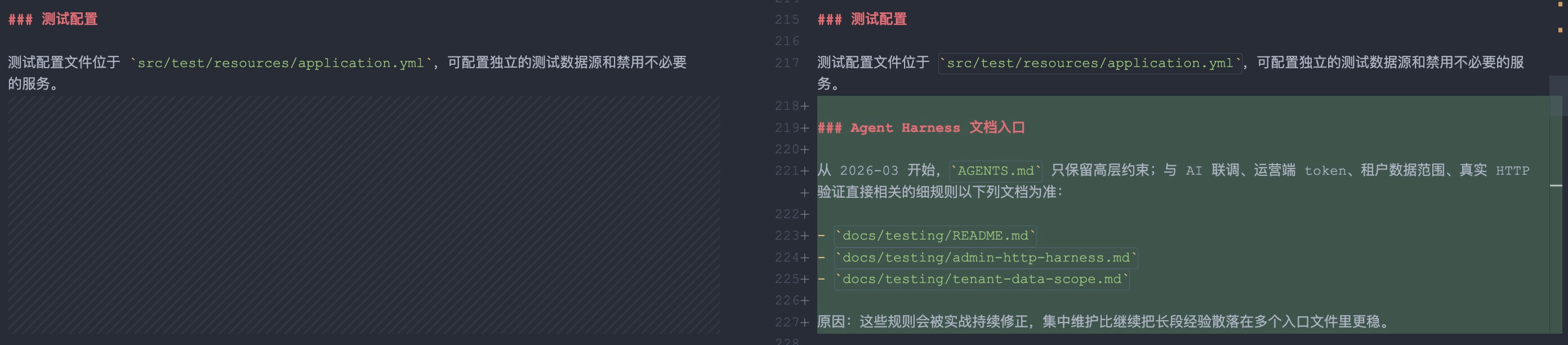
所以我这次顺手把项目里的规则做了一个调整:
AGENTS.md和CLAUDE.md保留高层原则- 具体的联调、token、租户、契约规则下沉到
docs/testing/
这不是为了“文档好看”,而是为了让规则能被持续修正,而不是散落在三个地方互相漂移。
3)真正有价值的,不是“写了规则”,而是“规则能被验证”
如果规则只是:
- 显式传
tenantId - 统一走网关
- 做真实 HTTP 测试
那它还是有点抽象。
真正有效的规则必须长成下面这样:
- 运营端接口测试时,直接向用户索取运营端 token
- 同一个 token,对照请求
tenantId=A/B - 至少保留一条原始 HTTP 响应
- 必要时补查数据库解释“为什么接口返回这样”
一旦规则写到这个粒度,AI 和人都更难自欺欺人。
三、这次我把项目规则怎么改了
结合这次联调前后对比,我最后把项目里的规则改成了三层。
第一层:入口文档只讲方向,不再堆细则
我在项目根目录 AGENTS.md 和 goodsop-app-server/CLAUDE.md 里增加了一个明确入口:
docs/testing/README.mddocs/testing/admin-http-harness.mddocs/testing/tenant-data-scope.md
意思很简单:
入口文档只负责告诉 AI“去哪儿看”,真正经常变化的实战规则集中维护。
第二层:把运营端 HTTP harness 写成可执行规则
这次新增的 admin-http-harness.md 里,我重点固化了几件事:
- 所有运营端联调统一走
http://localhost:9999 - 测试运营端接口时,必须直接问用户要 token
- 同一轮验证里,优先用同一个 token 只切换 query
tenantId - 每次改动至少保留 1 个真实业务接口的原始响应
- 失败排查顺序固定为:连通性 -> 网关 -> Nacos -> 鉴权上下文 -> 业务代码/SQL
这几条看起来朴素,但非常关键。因为 agent 一旦没有这些硬边界,就会在“如何拿 token”“是不是该直连服务”“这个请求到底算不算验证”上浪费很多轮次。
第三层:把租户数据范围语义写明白
tenant-data-scope.md 里,我把这次最核心的结论直接写死了:
- 后台管理接口的数据范围以显式传入的目标
tenantId为准 TenantContextHolder是上下文机制,不是后台业务真相checkName/checkPhone必须同时校验接口契约和逻辑删除语义
尤其是第三点,这次特别有代表性。
我们一开始看到有些门店名“库里明明有记录,接口却返回可用”,很容易怀疑代码没改对。
后来一查数据库才发现:那几条是逻辑删除记录。也就是说,数据库里有行,不等于业务上仍占用名称。
这个结论如果不被写进规则里,下次还会重复争论。
四、这次代码层面的前后对比,也很说明问题
如果只看代码,这次改动其实不算复杂,核心就是两件事。
改动前
- Controller 收到了
tenantId - 但部分 service 逻辑还是依赖
TenantContextHolder checkName的返回在失败时没有稳定给出data=false- 联调时容易把“请求头租户”“目标业务租户”“逻辑删除记录”混在一起
改动后
admin/store/*、admin/consultant/*显式把tenantId往下传- 需要上下文的地方用
TenantBroker.applyAs(tenantId, ...) checkName改成:- 可用:
data=true - 不可用:
data=false
- 可用:
- 真实接口回归不只看代码,还做了:
tenantId=5584与tenantId=1对照请求- 门店新增、关店、员工新增、修改、离职
- 必要时补查 PG 解释结果
这里最关键的,不是“把某个 if 改对了”,而是从“我觉得这样应该对”变成了“我能证明它对,而且能解释为什么”。
这就是 harness 的价值。

五、对我们这种业务项目来说,AI 真正缺的不是智商,而是工作台
很多人谈 AI Coding,喜欢把重点放在模型选择、prompt 技巧、上下文窗口大小。
这些当然重要,但我现在越来越觉得,对真实业务项目来说,下面这些东西更值钱:
1)可直接使用的环境入口
- 正确的网关地址
- 正确的 token 获取方式
- 正确的数据库连接信息
- 正确的日志和服务发现排查路径
2)可复用的验证脚本或验证模板
不是“你自己去测一下”,而是给出:
- 请求地址
- header
- body
- 对照 tenantId
- 预期差异
3)不会漂移的规则系统
很多团队的问题不是没有规则,而是规则散在聊天记录、群公告、项目文档、某个人脑子里。
一旦 AI 进场,这种问题会被放大得更厉害。
因为 AI 特别依赖“哪个文档才是 system of record”。
六、我准备继续往前做的,不只是写博客
这次规则改完以后,我更想补的是一套更完整的 harness,而不只是几段说明文档。
如果继续做,我下一步大概率会补这些东西:
scripts/verify-admin-store.sh- 自动完成
page/checkName/create/close
- 自动完成
scripts/verify-admin-consultant.sh- 自动完成
page/checkPhone/create/update/resign
- 自动完成
- 运行态环境说明
- 当前服务实际连接哪套 PG/Redis
- 接口契约回归样例
- 尤其是
data/code/msg这种容易被误解的接口
- 尤其是
因为写到最后我越来越确信一件事:
AI 工程化的竞争力,不是“谁的模型更像天才”,而是“谁先把自己的真实环境整理成一个不会误导 agent 的工作台”。
结语
OpenAI 那篇文章给我的最大提醒,是别把 agent 当成一个只会补代码的聊天机器人。
它更像一个能力很强、速度很快,但极度依赖环境质量的工程协作者。
如果你的环境是模糊的:
- 文档入口混乱
- token 获取方式混乱
- 租户语义混乱
- 接口契约混乱
那 AI 就会在这些噪音里反复打转。
但如果你把 harness 补起来,很多原来需要人肉盯着的事情,就会突然顺很多。
所以这次一个看似普通的 tenantId bug,最后给我的启发反而比 bug 本身更大:
以后优化 AI Coding,不只是继续追模型,也要继续做环境。