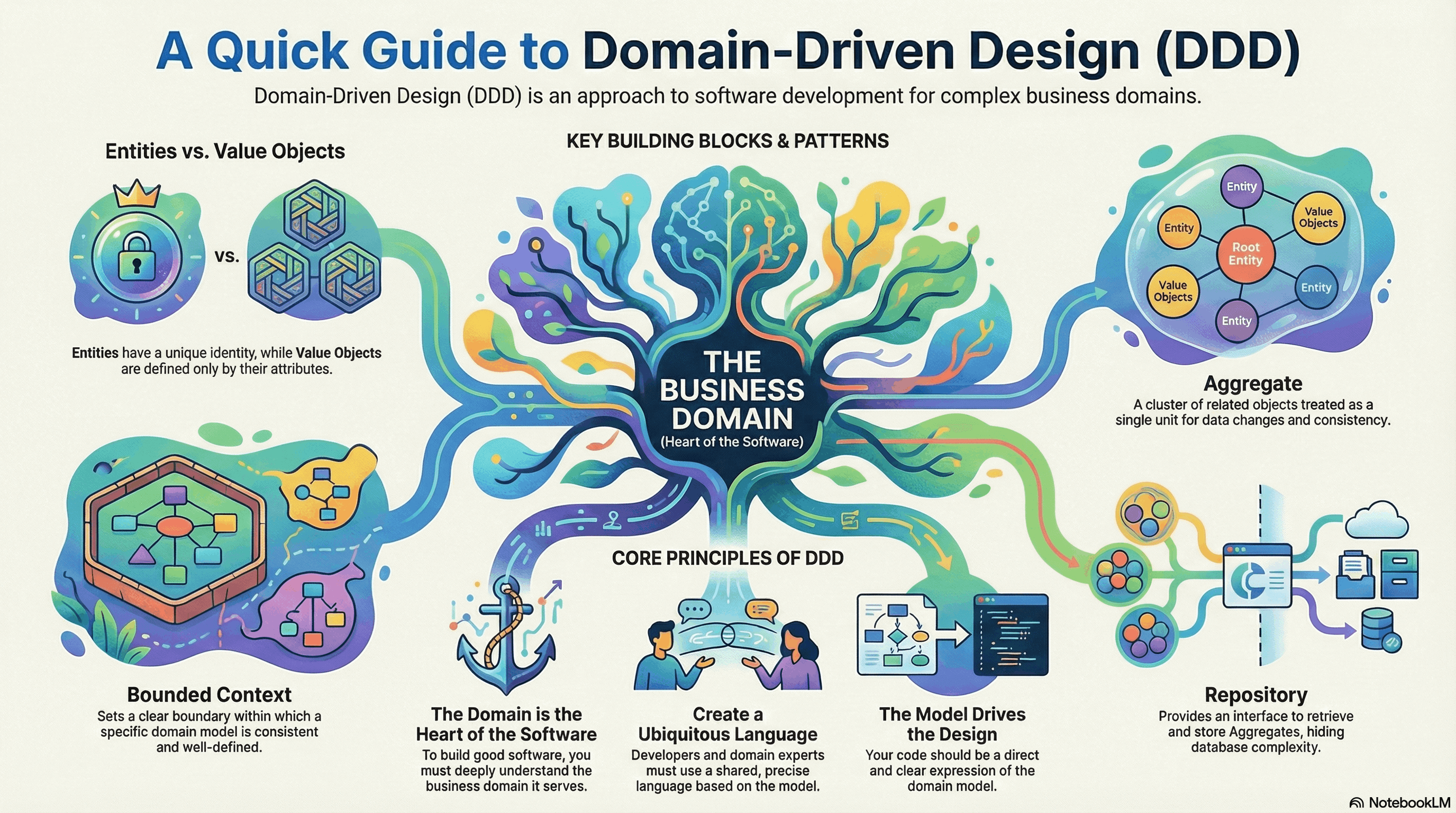
设计: 领域层只定义接口 findOrder(id),不关心底层是 SQL Server 还是 Oracle。资源库负责从数据库中检索数据并将其重建为领域对象(如 Order 聚合)。这让开发人员可以像从内存集合中获取对象一样获取领域对象,而无需在业务逻辑中编写 SQL,。
David Laribee 明确指出:**”持久化是基础设施”(Persistence is infrastructure)。Repository 的价值在于阻止 SQL 语句或存储过程等持久化概念混入领域模型。他同时指出,很多人会声称”数据库就是模型”——这在高度规范化并辅以图形化工具时确实能传达很多领域信息,但纯数据建模技术(如 ERD 或类图)无法展现一个领域中固有的行为**——你需要看到模型的各部分如何运动、类型之间如何协作来完成工作[^2]。
如果想深入学习 DDD,了解谁是真正的”意见领袖”非常重要。以下是技术界公认的 Top 级人物与他们的核心阵地:
1. Eric Evans —— DDD 的开创者(”蓝皮书”作者)
毫无疑问,Eric Evans 是 DDD 的”亲生父亲”。他在 2003 年出版了奠基之作《领域驱动设计:软件核心复杂性应对之道》(Domain-Driven Design: Tackling Complexity in the Heart of Software),也就是技术圈常说的**”蓝皮书”**。
所在机构: 创立了 Domain Language 咨询公司,至今依然在世界各地的顶级技术会议上发表 DDD 相关演讲。
经典思想: “将知识碾碎进模型”(Crunching Knowledge into Models)——代码是领域理解的不断演进,而非一次性的需求文档翻译[^2]。
2. Vaughn Vernon —— DDD 落地实践的第一人(”红皮书”作者)
如果说 Eric Evans 定义了 DDD 的理论框架,那 Vaughn Vernon 就是将 DDD 真正工程化、可落地的关键人物。
核心著作: 《实现领域驱动设计》(Implementing Domain-Driven Design,2013),被称为**”红皮书”**。这本书极大地补充了蓝皮书中缺失的实操细节和代码示例。后续又出版了《Reactive Messaging Patterns with the Actor Model》和《Strategic Monoliths and Microservices》。
Every modern application relies on data, and users expect that data to be fast, current, and always accessible. However, databases are not magic. They can fail or slow down under load. They can also encounter physical and geographic limits, which is where replication becomes necessary.
Database Replication means keeping copies of the same data across multiple machines. These machines can sit in the same data center or be spread across the globe. The goal is straightforward:
Increase fault tolerance
Scale reads
Reduce latency by bringing data closer to where it’s needed
Replication sits at the heart of any system that aims to survive failures without losing data or disappointing users. Whether it’s a social feed updating in milliseconds, an e-commerce site handling flash sales, or a financial system processing global transactions, replication ensures the system continues to operate, even when parts of it break.
However, replication also introduces complexity. It forces difficult decisions around consistency, availability, and performance. The database might be up, but a lagging replica can still serve stale data. A network partition might make two leader nodes think they’re in charge, leading to split-brain writes. Designing around these issues is non-trivial.
复制策略概述 | Overview of Replication Strategies
在分布式数据库中,有三种主要的复制策略:
In distributed databases, there are three main replication strategies:
1. 单主复制 (Single-Leader Replication)
工作原理 | How It Works:
一个主节点接收所有写入操作
主节点将更改复制到多个从节点
从节点提供读取服务
优势 | Advantages:
简单且易于理解
强一致性保证
避免写入冲突
劣势 | Disadvantages:
主节点成为单点故障
写入性能受限于单个节点
主节点故障时需要故障转移
One primary node accepts all writes
Primary replicates changes to multiple secondary nodes
Replication lag is a key challenge faced by distributed databases. When the primary node receives a write and propagates changes to replicas, there’s a time delay. This lag can lead to:
读取后写入不一致 | Read-After-Write Inconsistency
用户写入数据后立即读取可能看到旧数据。
Users might see stale data when reading immediately after writing.
单调读取问题 | Monotonic Read Issues
用户可能看到数据”倒退”,即先看到新数据后看到旧数据。
Users might see data “go backwards” - seeing newer data then older data.
因果关系违反 | Causality Violations
相关事件可能以错误的顺序出现。
Related events might appear in the wrong order.
选择合适的复制策略 | Choosing the Right Replication Strategy
何时选择单主复制 | When to Choose Single-Leader Replication
需要强一致性的应用
写入量相对较低
简单的故障转移需求
Applications requiring strong consistency
Relatively low write volume
Simple failover requirements
何时选择多主复制 | When to Choose Multi-Leader Replication
多数据中心部署
高写入可用性需求
可以容忍冲突解决的复杂性
Multi-datacenter deployments
High write availability requirements
Can tolerate conflict resolution complexity
何时选择无主复制 | When to Choose Leaderless Replication
最终一致性可接受
需要高可用性
简单的扩展需求
Eventual consistency is acceptable
High availability is needed
Simple scaling requirements
实现考虑因素 | Implementation Considerations
一致性模型 | Consistency Models
强一致性: 所有副本始终同步
最终一致性: 副本最终会收敛
因果一致性: 保持事件的因果关系
Strong Consistency: All replicas always in sync
Eventual Consistency: Replicas eventually converge
Causal Consistency: Maintains causality between events
冲突解决策略 | Conflict Resolution Strategies
最后写入获胜 (LWW): 基于时间戳的简单策略
应用层解决: 让应用程序处理冲突
合并策略: 自动合并冲突的更改
Last Write Wins (LWW): Simple timestamp-based strategy
Application-level resolution: Let application handle conflicts
In real projects, PostgreSQL as an enterprise-grade open-source database has unique advantages in replication. Through my experience with PostgreSQL replication in multiple projects, I have the following insights:
While multi-leader and leaderless replication are theoretically attractive, in actual production environments, I find single-leader replication is still the most reliable choice, especially for business scenarios requiring strong consistency. Here’s why:
复杂性可控: 单主复制的逻辑简单,故障排查容易
一致性保证: 避免了复杂的冲突解决机制
工具成熟: PostgreSQL的单主复制工具链非常成熟
性能可预测: 读写分离的性能模式清晰
Manageable complexity: Single-leader replication logic is simple, easy to troubleshoot
Database replication is a fundamental technology for building reliable, scalable systems. Choosing the right replication strategy depends on your application’s specific requirements, including consistency needs, availability goals, and performance expectations. Understanding the trade-offs of each approach is crucial for designing successful distributed systems.
Based on my practical experience with PostgreSQL replication, I strongly recommend: Start simple, optimize gradually. First establish a stable single-leader replication architecture, then gradually introduce more complex replication strategies based on business growth and performance requirements. PostgreSQL as an enterprise-grade database, its replication features can fully meet the needs of most business scenarios.
Regardless of which strategy you choose, careful consideration of implementation details, monitoring system health, and preparing for failure scenarios is essential. As applications evolve, replication strategies may need to evolve as well to meet new requirements.
/3.jpg "https://www.6clicks.com")
/1.jpg "danielp1.substack.com")
/2.webp "k2view.com")